



Is it possible to mine Twitter for information and trends on outbreaks of food poisoning? One data scientist at Google believes this is the case. Adam Sadilek recently headed a team at the University of Rochester that developed a machine learning system called Nemesis, which asked ‘which restaurants should be avoided today?’
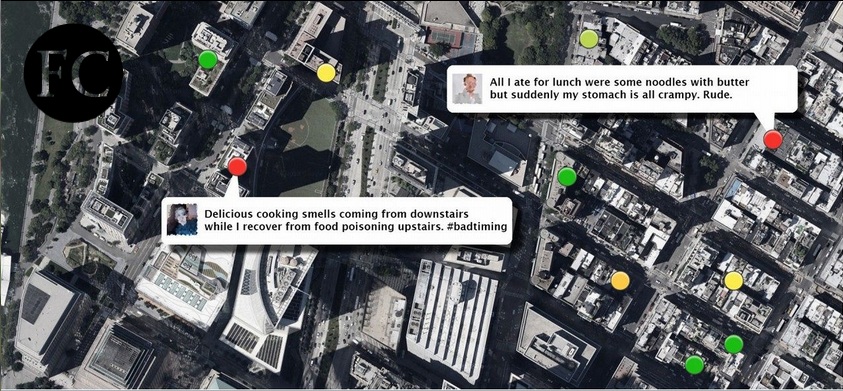
Using several keywords, Nemesis began to mine Twitter for geolocated posts that might indicate some type of foodborne illness. In several tests, tweets from New York and other places were datamined. Metadata was added to indicate restaurants within 50 feet that were open at the time the user was tweeting. A team of researchers then came up with 30 words and phrases that indicated there was food poisoning. These phrases included ‘my tummy hurts,’ ‘throw up,’ and ‘Pepto-Bismol.’ Nemesis than tagged health scores onto each restaurant that was nearby, based upon the proportion of tweets that inferred food poisoning.
The interesting part of this project was that the scores that were given to the restaurants were in alignment with data from the Health Department in New York. The health scores from Nemesis actually correlated closely with the letter grade from the Health Department.
Public health experts also have been taking note of the huge pool of self generated data in Twitter as a way to possibly track the spread and origins of many diseases.

One of the biggest advantages of Twitter is that it is so fast. Regular methods of collecting health information often lag because the researchers usually have to wait for much data from health organizations and hospitals. They also have to wait for information from sources that are related to consumer behavior, such as buying drugs and medical products. However, how can we collect information from people who do not go to the doctor? How can we effectively track such diseases and illnesses? How to get the information quicker?
Fortunately, Twitter allows us to do this. All information that is collected on Twitter is available, real time and is tagged with a location. So, Twitter can know when a person wakes up, say, with a stomach problem in Boston, because they have written about it on Twitter.
If this sort of data can be properly collected and analyzed, it can help to keep medical facilities from being overwhelmed during a serious disease outbreak. Also, hospitals might be able to get a heads up that a disease is ramping up in a certain location, and they would then be able to stock up on needed drugs and on staff. The Washington Post also has reported that such location-specific data can also ID pockets of diseases that are noncommunicable, which will allow health officials to put more focus on education efforts in areas that most need it.
Also, Twitter can be a wonderful tool in parts of the country that do not have good public health monitoring tools.
Some researchers to this point have been a bit hesitant to embrace the data of Twitter. Some say that it is just too messy and uncontrollable when you compare it to other public health data efforts. However, others say that the messiness that some do not like is the big strength of Twitter.
The reason for this is that people Tweet about everything. Twitter makes it so easy to talk about what is on your mind, it truly is like a pulse on the world.


